팀프로젝트 중 Redis를 사용해야하는 상황이 있었는데 팀원들과 스터디를 진행하기로 해서 미리 개념을 알아보고자 한다.
팀 프로젝트에서 Redis를 사용하기로 했다. 팀원들과 본격적인 스터디를 진행하기 전에 기본 개념을 미리 알아두면 좋을 것 같아서 정리해본다.

Redis란?
Redis는 Remote Dictionary Server의 약자로, 메모리 기반의 키-값(Key-Value) 구조 데이터 저장소다.
쉽게 말하면 데이터를 메모리(RAM)에 저장해서 빠르게 읽고 쓸 수 있는 데이터베이스라고 생각하면 된다. 일반적인 데이터베이스가 디스크에 데이터를 저장하는 것과 달리, Redis는 메모리에 저장하기 때문에 접근 속도가 매우 빠르다.
오픈소스이고 BSD 라이선스를 따르기 때문에 무료로 사용할 수 있다는 점도 장점이다.
그렇다면 일반 데이터베이스와 정확히 어떤 차이가 있을까? 표로 정리해보면 한눈에 비교할 수 있다.

보다시피 Redis는 속도에 특화되어 있고, 일반 DB는 안정적인 데이터 보관에 강점이 있다. 그래서 실제로는 둘을 함께 사용하는 경우가 많다. Redis로 자주 조회되는 데이터를 캐싱하고, DB에는 원본 데이터를 영구 저장하는 식으로 말이다.
왜 쓰나요?
가장 큰 이유는 속도 때문이다.
일반적인 데이터베이스(MySQL, PostgreSQL 등)는 디스크에서 데이터를 읽어오는데, 디스크 I/O는 상대적으로 느리다. 반면 Redis는 메모리에서 데이터를 읽기 때문에 마이크로초(microsecond) 단위의 응답 속도를 제공한다.

이런 특성 때문에 주로 다음과 같은 상황에서 사용한다:
- 캐싱(Caching): 자주 조회되는 데이터를 Redis에 저장해두고, DB 조회 횟수를 줄인다
- 세션 관리: 로그인 세션 정보를 빠르게 저장하고 조회한다
- 실시간 랭킹: 게임이나 서비스의 실시간 순위를 관리한다
- 메시지 큐: 데이터를 임시로 저장하고 처리하는 용도로 사용한다
어떤 자료구조를 지원하나요?
Redis가 단순한 Key-Value 저장소와 다른 점은 다양한 자료구조를 지원한다는 것이다.

1. String
가장 기본적인 형태로, 하나의 키에 하나의 값을 저장한다.
SET user:1000 "홍길동"
GET user:1000 // "홍길동" 반환2. List
순서가 있는 문자열 리스트다. 양쪽 끝에서 push/pop이 가능하다.
LPUSH mylist "first"
RPUSH mylist "second"3. Set
중복되지 않는 문자열의 집합이다.
SADD myset "apple"
SADD myset "banana"
SADD myset "apple" // 중복이라 추가되지 않음4. Hash
필드-값 쌍으로 구성된 해시 테이블이다. 객체를 표현하기 좋다.
HSET user:1000 name "홍길동"
HSET user:1000 age "25"
HGET user:1000 name // "홍길동" 반환5. Sorted Set
스코어를 기준으로 정렬되는 집합이다. 랭킹 시스템에 유용하다.
ZADD ranking 100 "user1"
ZADD ranking 200 "user2"
ZRANGE ranking 0 -1 // 스코어 순으로 정렬된 결과데이터가 메모리에만 있으면 사라지지 않나요?
맞다. 메모리는 휘발성이기 때문에 서버가 재시작되면 데이터가 사라질 수 있다. 하지만 Redis는 이를 위한 영속성(Persistence) 기능을 제공한다.

RDB (Redis Database)
특정 시점의 스냅샷을 디스크에 저장한다. 마치 사진을 찍듯이 그 순간의 데이터를 저장하는 방식이다.
장점: 파일 하나로 백업이 간단하고, 복구 속도가 빠르다 단점: 스냅샷 사이에 장애가 발생하면 그 사이 데이터는 손실된다
AOF (Append Only File)
모든 쓰기 작업을 로그 파일에 기록한다. 모든 변경사항을 순차적으로 기록하는 방식이다.
장점: 데이터 손실이 거의 없다 단점: RDB보다 파일 크기가 크고, 복구 속도가 느릴 수 있다
우리 프로젝트에서는 어떤 방식을 사용할지 팀원들과 논의해봐야겠다.
Redis는 언제 사용하면 좋을까요?
실제 사용 사례를 생각해보면 이해가 쉽다.
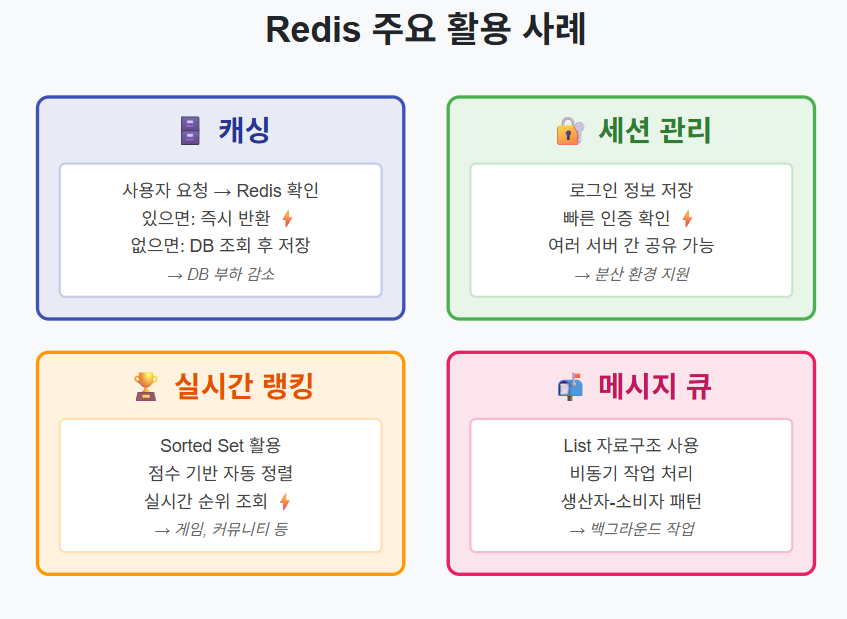
캐싱 시나리오
블로그 포스트를 생각해보자. 인기 있는 포스트는 수천 명이 동시에 조회할 수 있다. 매번 DB를 조회하면 부하가 크다.
- 1. 사용자가 포스트 조회 요청
- 2. Redis에 해당 포스트가 있는지 확인
- 3-1. 있으면 Redis에서 바로 반환 (캐시 히트)
- 3-2. 없으면 DB에서 조회 후 Redis에 저장하고 반환 (캐시 미스)
이렇게 하면 DB 부하를 크게 줄일 수 있다.
세션 관리
로그인 상태를 관리할 때도 유용하다. 세션 정보를 Redis에 저장하면:
- 빠른 조회 가능
- 만료 시간(TTL) 설정 가능
- 여러 서버에서 세션 공유 가능 (분산 환경)
실시간 랭킹
게임이나 커뮤니티의 실시간 랭킹 기능에 Sorted Set을 활용할 수 있다.
ZADD game_ranking 1500 "player1"
ZADD game_ranking 2000 "player2"
ZREVRANGE game_ranking 0 9 // 상위 10명 조회주의할 점은 없나요?
물론 있다. 메모리 기반이기 때문에 생기는 제약사항들이다.

1. 메모리 용량 제한
메모리는 디스크보다 비싸고 용량이 제한적이다. 모든 데이터를 Redis에 넣을 수는 없다.
2. 메모리 관리
메모리가 가득 차면 어떻게 할지 정책을 설정해야 한다:
- noeviction: 쓰기 거부
- allkeys-lru: 가장 오래된 키부터 삭제
- volatile-lru: 만료 시간이 설정된 키 중 가장 오래된 것부터 삭제
3. Single Thread
Redis는 기본적으로 단일 스레드로 동작한다. 하나의 명령어가 오래 걸리면 다른 요청들이 대기하게 된다. 그래서 복잡한 연산은 피하는 게 좋다.
'Archive > Java 풀스택 아카데미' 카테고리의 다른 글
| [TIL] 22. 12월 Axios Interceptor (문제해결) (1) | 2025.12.16 |
|---|---|
| [TIL] 21. 12월 S3란? (1) | 2025.12.08 |
| [TIL] 19. 11월 JPA란 (0) | 2025.11.25 |
| [TIL] 18. 11월 JWT (0) | 2025.11.18 |
| [TIL] 17. 11월 Spring Security (0) | 2025.11.11 |



